We Built a Feed Ranking Algorithm From Open-Source Parts. Here's the Formula.
Every company feed starts the same way. Someone ships a chronological list of events, calls it a "feed," and watches engagement flatline within two weeks.
The problem isn't the events. It's the ordering. A chronological feed treats a first-ever workout from a new teammate the same as someone's 47th completion this week. Your brain doesn't work that way. Neither should the feed.
We spent a month studying open-source ranking algorithms before writing a single line of code. Here's what we found, what we stole, and the formula we ended up with.
Ready to develop your team's voice?
Start a free trial →The algorithms we studied
Four open-source approaches shaped our thinking, each solving a different piece of the puzzle:
EdgeRank — Facebook's original formula (circa 2011, now open-sourced as Nikola352/EdgeRank). The foundation: Affinity × Weight × Decay. Simple enough to compute at query time, expressive enough to feel personal. The insight that proximity between people should drive feed relevance — that was EdgeRank's gift to us.
X's recommendation pipeline — when X open-sourced their algorithm (16K+ stars on GitHub), the interesting part wasn't the ML models. It was the pipeline architecture: Source → Hydrate → Filter → Score → Select → Post-Filter. Composable stages that you can reason about independently. And their Author Diversity Scorer — the idea that no single person should dominate your feed, no matter how active they are.
Hacker News gravity scoring — score / (age + 2)^gravity. Beautifully simple time decay without hard cutoffs. Events don't suddenly disappear at the 24-hour mark. They fade naturally, the way recency works in human memory.
Reddit's Wilson Score Interval — Evan Miller's famous essay on why you shouldn't sort by average rating. One reaction on a new event shouldn't outrank fifty reactions on another. Wilson Score gives you confidence-adjusted popularity, which prevents early-bird bias in engagement signals.
The formula
Every feed event gets a personalized score for each viewer:
FeedScore = Affinity × EventWeight × TimeDecay × EngagementBoost × DiversityPenaltyfive components, each borrowed from a different algorithm, each solving a specific problem. let's break them down.
Affinity: your team matters more
This is the biggest signal. Adapted from EdgeRank's core insight — the relationship between viewer and author determines relevance.
Same direct team: 0.8. Same parent team: 0.5. Same org branch: 0.3. Different team entirely: 0.1.
But static proximity isn't enough. We layer in two dynamic boosts:
- reporting relationships — direct reports get +0.2, direct managers get +0.15. Because when your manager completes a workout, you notice. And when your report hits a personal best, you want to know.
- interaction history — have you reacted to this person's events before? Been coaching partners? Practiced the same workouts? Up to +0.2 from accumulated interaction signals.
The interaction history turns the feed into a learning system. The more you engage with someone's content, the more their content surfaces for you. No ML required — just counters in a Supabase table that increment on specific triggers.
Event weight: not all achievements are equal
A personal best is rarer and more meaningful than a routine workout completion. The weights reflect that:
Personal bests get 3.0×. Milestone workouts (10th, 25th, 50th, 100th) get 2.5×. Streak milestones and skill level-ups get 2.0×. Completed coaching sessions get 1.8×. Regular workout completions — the bread and butter — get 1.0×.
There's a viewer-specific adjustment too. If you consistently react to personal best events, the system boosts PB weight by up to 30% for you specifically. Lightweight personalization through reaction pattern analysis.
Time decay: gaussian, not linear
Linear decay creates a cliff — events go from relevant to invisible overnight. We use Gaussian decay with a 12-hour half-life instead:
decay = e^(-0.693 × (age / halfLife)²)at 12 hours, an event retains 50% relevance. at 24 hours, 25%. at 36 hours, 12.5%. the curve mirrors how humans actually process recency — a gradual fade, not a hard cutoff. GetStream and Facebook both use Gaussian for this reason.
Engagement boost: Wilson Score prevents gaming
Reactions are a signal that something is worth seeing. But raw reaction counts are misleading — an event with 1 reaction posted 5 minutes ago isn't necessarily better than one with 50 reactions posted yesterday.
Wilson Score Interval gives us a confidence-adjusted engagement signal. The formula calculates a lower bound on the "true" reaction rate given the sample size. One reaction out of 100 possible viewers gives a very different signal than one reaction out of 3 possible viewers.
The boost ranges from 1.0× (no reactions) to 2.0× (significant, statistically confident engagement). This prevents both early-bird bias and popularity cascades.
Get insights from The Lab
Weekly research on voice science, executive communication, and leadership development.
No spam, unsubscribe anytime.
Diversity penalty: borrowed from X
Without this, a power user who completes 5 workouts in a day would dominate the feed with 5 consecutive entries. X's Author Diversity Scorer solves this elegantly:
First event from an author: no penalty (1.0×). Second event: 0.7×. Third: 0.5×. Fourth and beyond: 0.3×.
The penalty applies within the current page window, not globally. So a prolific user's events still appear — just spread across multiple page loads instead of clustered at the top.
The pipeline
Scoring is one step in a six-stage pipeline adapted from X's composable architecture:
- candidate sourcing — pull last 200 events from the viewer's company. Wider window than page size gives the ranking engine headroom.
- privacy filtering — remove events from opted-out users, hidden event types, restricted teams. Three-level privacy: company settings AND team settings AND individual settings. Most restrictive wins.
- hydration — batch-fetch author profiles, reaction counts, viewer's existing reactions, team membership, interaction history. All in parallel.
- scoring — compute personalized FeedScore for each candidate.
- selection — sort by score, apply category filters, take top 20.
- dedup — remove near-duplicates, group batch events ("5 people completed Stakeholder Alignment today").
The entire pipeline runs in a Supabase Edge Function. No external services, no ML inference calls, no cold starts. Just math on data that's already in the database.
Why not machine learning
This is the question we get from every engineer who looks at the formula. Why a weighted scoring function instead of a neural network?
Three reasons:
signal space is small and well-defined. we have team membership, reporting hierarchy, interaction history, event types, timestamps, and reaction counts. That's the universe of inputs. A neural network trained on these features would converge to something very close to our formula — but with less interpretability and more infrastructure.
scale doesn't justify it. our companies have 25 to 1,000 users. ML models need millions of interactions to outperform a well-tuned formula. At our scale, we'd be overfitting, not learning.
explainability matters. when a team admin asks "why is this event showing at the top?" we can answer: "it's a personal best (3.0× weight) from someone on your direct team (0.8 affinity) posted 2 hours ago (0.97 decay) with 7 reactions (1.4× engagement boost)." try explaining that with a transformer model.
We're not anti-ML. When companies hit 10K+ users and we have enough interaction data for collaborative filtering to add real value, we'll layer it in. Formula-based ranking is the right tool for the right scale.
What we learned building it
The ranking formula took three iterations to get right. The first version over-weighted affinity and turned the feed into a team echo chamber. The second over-weighted time decay and made it functionally chronological. The third — the current one — balances the components so that a high-affinity event from yesterday can still beat a low-affinity event from an hour ago, but only if the event is genuinely significant.
The diversity penalty was the last addition. Without it, we noticed that a single person doing a "workout sprint" would push everyone else off the feed for hours. X solved this exact problem, and their approach translated cleanly to our context.
The interaction history feedback loop was the most satisfying to build. Every reaction you give subtly shifts your future feed. Not dramatically — the boost caps at +0.2 — but enough that the feed feels increasingly personal over weeks of use. It's the kind of thing users feel but can't quite articulate. "the feed just gets me" is the reaction we're designing for.
Open-source algorithms gave us the vocabulary and the patterns. The formula is ours, tuned for the specific dynamics of workplace voice training. Standing on the shoulders of EdgeRank, X, HN, and Reddit — and building something that none of them quite needed to build.
Related Posts

Why We Built a Personalization Engine (And Why It Doesn't Use an LLM)
Most professional development platforms treat every user the same. We built a personalization engine grounded in Bayesian Knowledge Tracing, spaced repetition, and Zone of Proximal Development research — using a deterministic 5-factor scoring model instead of an LLM.
10 min read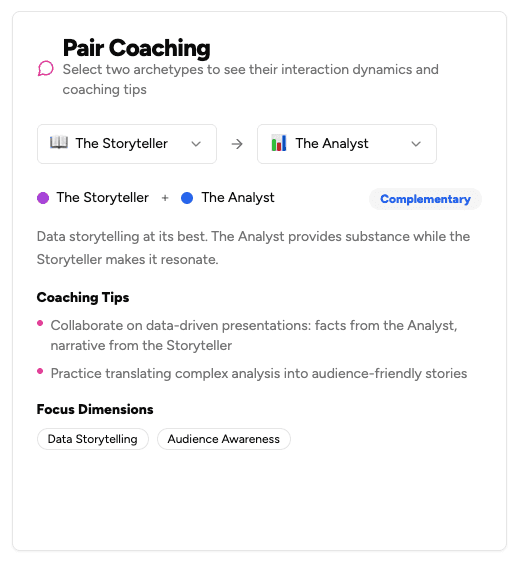
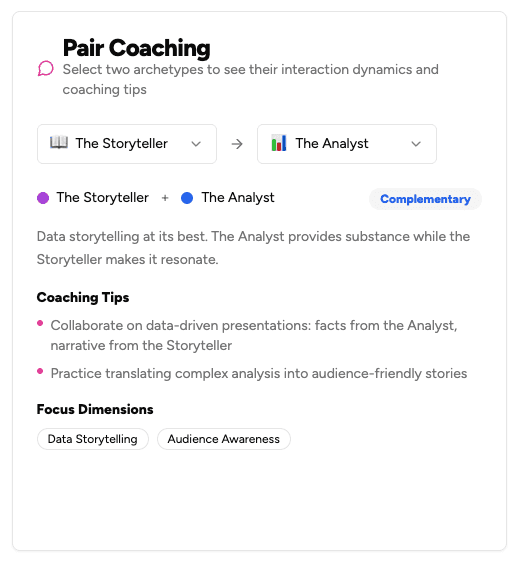
How We Built a Coaching Match Algorithm That Actually Works
Most team coaching tools pair people randomly or by manager fiat. We built a scoring algorithm rooted in communication archetype dynamics, wrapped it in behavioral science that drives action, and grounded the coaching structure in learning theory that actually sticks.
7 min readGet insights from The Lab
Weekly research on voice science, executive communication, and leadership development. No spam, unsubscribe anytime.