Why We Built a Personalization Engine (And Why It Doesn't Use an LLM)
The behavioral science, adaptive learning research, and 5-factor scoring model behind ExecReps' recommendation system
Here's a dirty secret about professional development platforms: they treat every user the same. A VP preparing for a board presentation and a first-time manager rehearsing a 1:1 see the same workout library. The same grid. The same "pick whatever looks interesting" experience.
It's like walking into a gym with 50 machines and no trainer — you wander, you try something random, you leave unsure if you did the right thing.
We know this because we watched it happen. Our beta users would complete one workout, get their AI score, return to the library, stare at 30+ options, and ask the same question:
Ready to develop your team's voice?
Start a free trial →"What should I do next?"
That question — asked by more users than any other — became the catalyst for everything that followed. So we built a personalization engine from first principles. And no, it doesn't use an LLM.
What the Research Says About Skill Development
Before writing a single line of code, we spent weeks studying the science of how people actually get better at complex skills. Not just any skill — communication, which is uniquely difficult because it involves simultaneous cognitive load (content structure, argument quality) and motor/performance load (vocal delivery, pacing, filler word suppression).
Three bodies of research shaped our approach.
Bayesian Knowledge Tracing: Knowing What You Know
Developed at Carnegie Mellon University's LearnLab, Bayesian Knowledge Tracing (BKT) is the mathematical backbone of adaptive learning systems like Carnegie Learning and Khan Academy. It models each skill as having a probability of mastery, updated after every attempt using Bayes' theorem.
The key insight for ExecReps: our dual-axis scoring system already generates exactly the data BKT needs. Every workout submission produces per-dimension scores across content categories (argument structure, evidence use, audience awareness) and delivery metrics (pace, fluency, filler words, confidence). These map directly to BKT skill nodes.
We don't need to guess what a user knows. We measure it — with voice AI that analyzes what humans hear.
Spaced Repetition: The Forgetting Curve Is Real
Hermann Ebbinghaus demonstrated in 1885 that memory decays exponentially without reinforcement. Modern systems like Duolingo's "Birdbrain" and Anki's FSRS algorithm have turned this into a science: the optimal time to review something is just before you forget it.
But communication skills aren't vocabulary flashcards. You don't "forget" how to structure an argument overnight. What does decay is the automaticity — the ability to do it fluently, under pressure, without conscious effort.
We adapted the spaced repetition model for performance decay. Delivery skills like pace and fluency decay faster than content skills like structure and evidence, because they're more motor-dependent. A user who scored 78 on "Executive Presence" three weeks ago might have an estimated current proficiency of 62 — and the engine knows it's time to practice.
Zone of Proximal Development: The Goldilocks Zone
Lev Vygotsky's 1930s concept of the Zone of Proximal Development (ZPD) has been validated across thousands of educational studies: learning is maximized when difficulty sits just beyond current ability — not so easy it's boring, not so hard it's frustrating.
The sweet spot? Research consistently shows 60–75% success rates maximize learning velocity. Below 40%, learners disengage. Above 85%, they coast. We built this directly into the recommendation engine.
What We Actually Built: The 5-Factor Scoring Model
Here's what surprises people: the recommendation engine doesn't use a large language model. It doesn't need one. It's pure business logic — deterministic scoring built on the rich data our existing voice AI already generates.
Every candidate workout is scored across five factors:
- Skill Match (40%) — How well does this workout target your weakest skills? This is the most sophisticated component: it cross-references your per-dimension scores from completed workouts against the skill targets of available workouts.
- Difficulty Fit (25%) — Is this workout in your Zone of Proximal Development? Every workout has a difficulty tier. Every user has an estimated level. The engine preferentially selects workouts one tier above current performance — stretching without breaking.
- Freshness (20%) — Are decaying skills being resurfaced at the right time? Skills you haven't practiced recently get a boost, weighted by their decay rate.
- Role Relevance (10%) — Does this match your seniority and context? A first-time manager and a C-suite exec need different scenarios.
- Exploration (5%) — A small random boost to ensure variety and discovery, preventing the engine from becoming too narrow.
The 40/25/20/10/5 weighting wasn't arbitrary. It emerged from our Opportunity Solution Tree analysis: the #1 user problem (scored 0.82 on importance × satisfaction gap) was "I don't know what to practice next." Skill matching directly addresses that. The #3 problem (0.65) was "I don't know if this is the right difficulty for me." Hence the 25% difficulty fit weight.
The Skill Taxonomy: Mapping Chaos to Structure
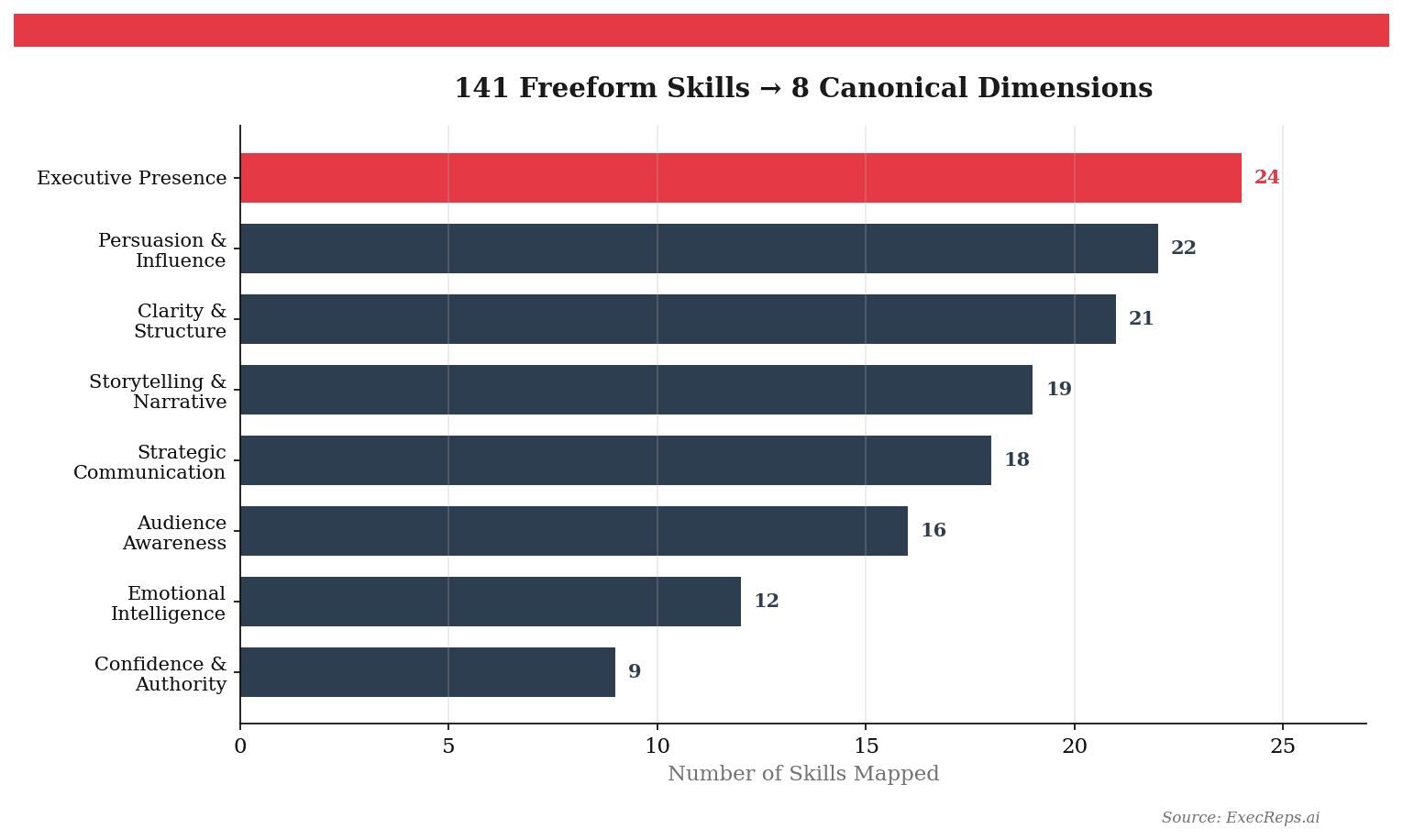
Before the engine could recommend by skill, we needed to solve a foundational problem: ExecReps had 141 unique freeform skill labels across its workout library. "Executive communication," "exec comm," "boardroom presence," and "C-suite presentation skills" were all separate strings describing overlapping competencies.
We mapped all 141 labels to 8 validated dimensions using a hybrid approach:
- O*NET Framework (U.S. Department of Labor) — The occupational taxonomy that maps skills across 900+ occupations. We selected the communication-relevant dimensions: Speaking, Active Listening, Persuasion, Social Perceptiveness, Negotiation, and Instructing.
- World Economic Forum Future of Jobs Report — Identifies the most valued professional skills through 2030. We added Analytical Thinking and Leadership/Social Influence.
- Gemini Embedding Classification — Each freeform label was embedded as a vector and classified to its nearest validated dimension using cosine similarity.
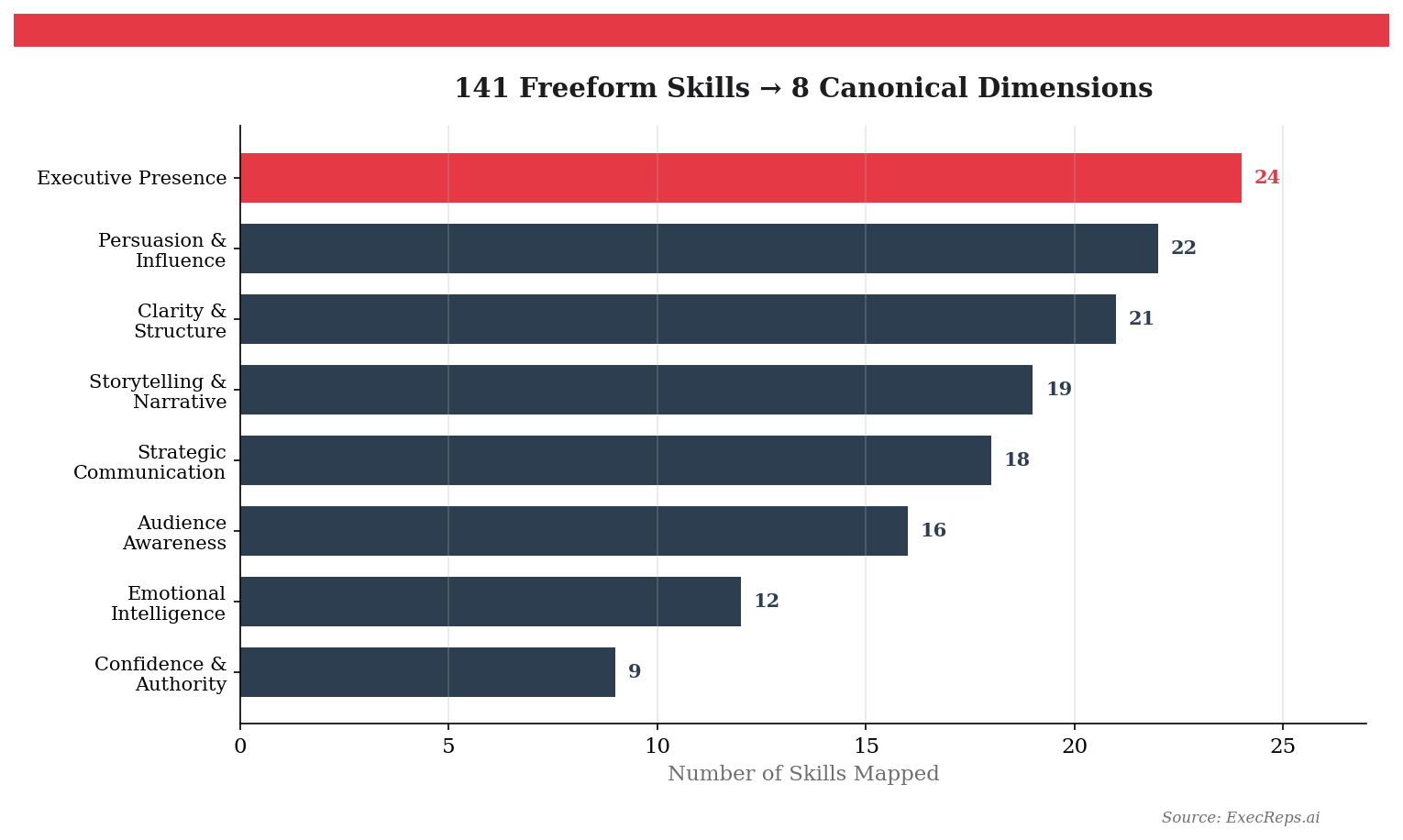
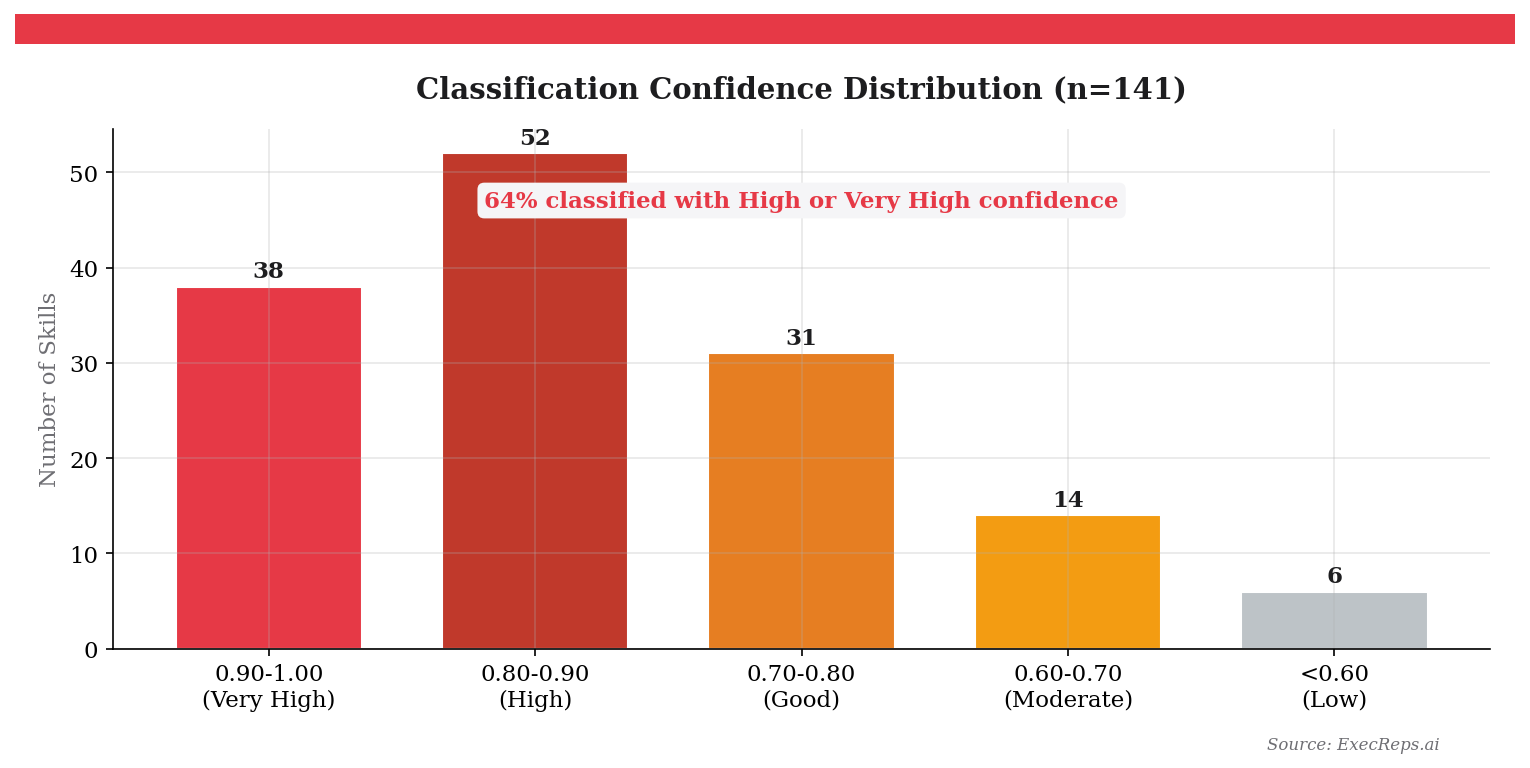
Average similarity score: 0.834 — meaning the automated classification closely matches what a human expert would assign.
The result: 8 clean dimensions that the recommendation engine can score, track, and surface. Every workout has a primary dimension and optional secondary targets. Every user accumulates a skill profile across all 8.
Cold Start: The First 60 Seconds Matter Most
New users have no score history. No skill gaps to target. No decay curves to model. This is the "cold start problem" — and how you solve it determines whether users stick around or bounce.
We solve it in onboarding with two screens that take under 30 seconds combined:
Challenge Picker: Six cards representing common communication challenges — "Thinking on my feet," "Being concise," "Executive presence," "Handling pushback," "Data storytelling," "Persuading stakeholders." Users tap their biggest challenge.
Confidence Sliders: Five sliders across core communication dimensions, each on a 1–10 scale. Research shows self-assessed confidence has only ~0.3 correlation with actual ability — so we don't trust these numbers as ground truth. Instead, they seed the engine's initial recommendations with a boosted exploration factor (0.30 vs. the standard 0.05). The engine starts broad, then converges as real performance data arrives.
This is the contextual bandit approach adapted from Netflix and Spotify: with a new user, explore widely. With an experienced user, exploit what works. The transition happens automatically as the recommendation log fills up.
The Data Architecture Behind It All
The engine is built on three new data structures, all additive to the existing schema:
Related Posts
How We Mapped 141 Freeform Skills to 8 Validated Dimensions
When your learning platform has 141 different skill labels, you can't build recommendations, track gaps, or show progress. Here's how we used O*NET, WEF, and Gemini embeddings to create a validated taxonomy — and why framework grounding matters more than model size.
7 min read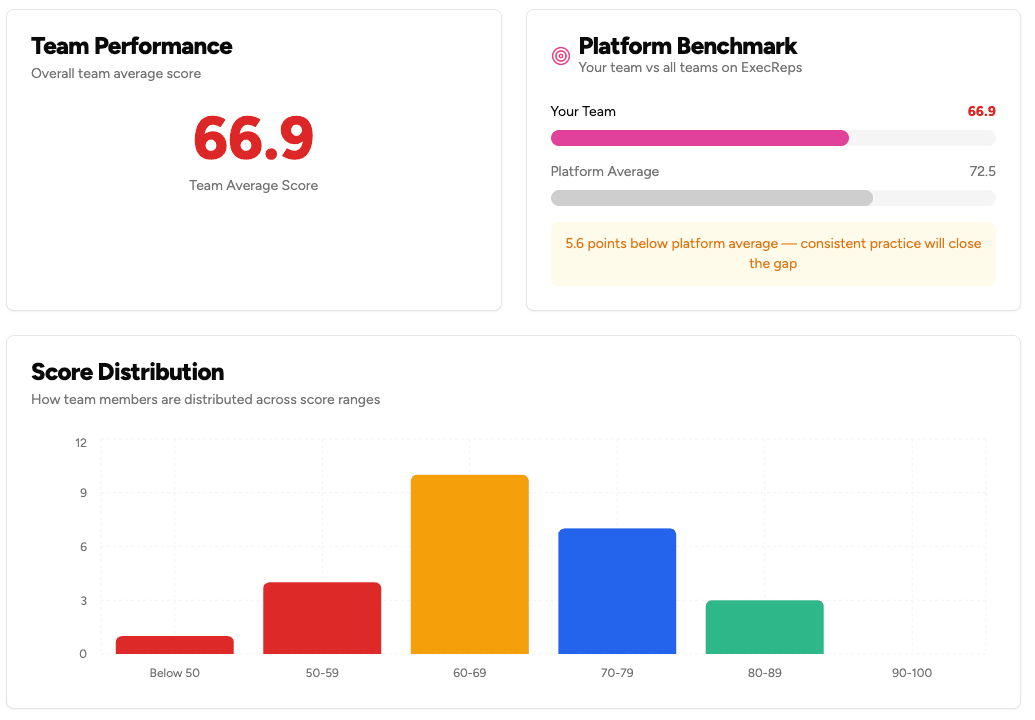
We Built a Feed Ranking Algorithm From Open-Source Parts. Here's the Formula.
We studied EdgeRank, X's open-source algorithm, Reddit's Wilson Score, and Hacker News gravity scoring. Then we built our own feed ranking formula for team activity feeds — no ML required.
8 min readGet insights from The Lab
Weekly research on voice science, executive communication, and leadership development. No spam, unsubscribe anytime.