How We Mapped 141 Freeform Skills to 8 Validated Dimensions
Standing on the shoulders of industrial psychologists, powered by sentence embeddings.
When we started building ExecReps, our workout library had a problem. Every workout had a "skill focus" — a freeform text field that described what the exercise trained. After 50 workouts, we had 141 unique labels. "Executive Presence." "C-Suite Alignment." "Persuasive Argumentation." "Stakeholder Buy-In." Some of these clearly overlap. Others don't. And no one — not even us — could tell you exactly how they all fit together.
This is a universal problem in learning platforms: your content grows faster than your taxonomy. And without a taxonomy, you can't build recommendations, track skill gaps, or show learners where they actually stand.
So we did what any self-respecting engineering team would do. We stole from the US Department of Labor.
Ready to develop your team's voice?
Start a free trial →The Taxonomy Problem
Here's what 141 freeform labels look like in practice. You have obvious clusters — "Persuasion," "Persuasive Communication," "Persuasion & Influence" are clearly the same thing. But what about "C-Suite Alignment"? Is that Executive Presence? Strategic Communication? Audience Awareness? The answer depends on context, and context is exactly what a flat text field doesn't give you.
The naive approach is to sit in a room and manually sort 141 cards into piles. We did that. It took hours and produced arguments. The second-naive approach is to throw an LLM at it and ask for categories. We did that too. It produced different categories every time.
What we needed was a ground truth — an established, peer-reviewed framework for categorising communication skills that existed before we did.
Standing on the Shoulders of Industrial Psychologists
Two frameworks turned out to be exactly what we needed.
The O*NET Content Model, maintained by the US Department of Labor, is the most comprehensive occupational skills taxonomy in existence. It decomposes "Communication" into precisely measurable sub-skills: Speaking, Persuasion, Negotiation, Active Listening, Social Perceptiveness. Each has a formal definition, measurement scale, and decades of validation data across every occupation in the US economy.
The World Economic Forum Global Skills Taxonomy takes a different angle — 93 skills across 5 hierarchical levels, designed to map the skills that matter for the future of work. It gives us "Persuasion and Negotiation," "Empathy and Active Listening," "Leadership and Social Influence" as distinct, measurable categories.
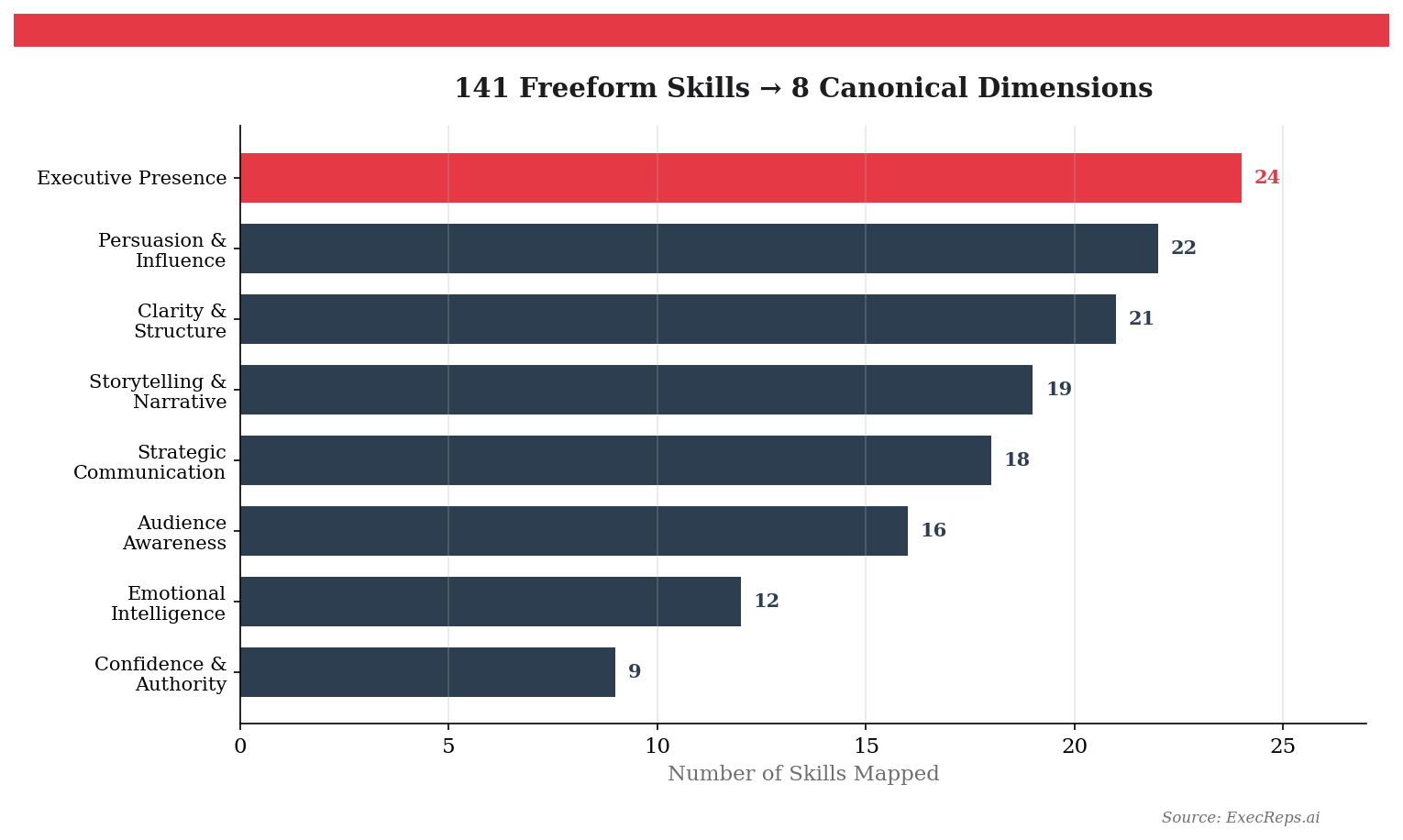
By synthesising these two frameworks, we derived 8 canonical dimensions that cover the full space of executive communication skills:
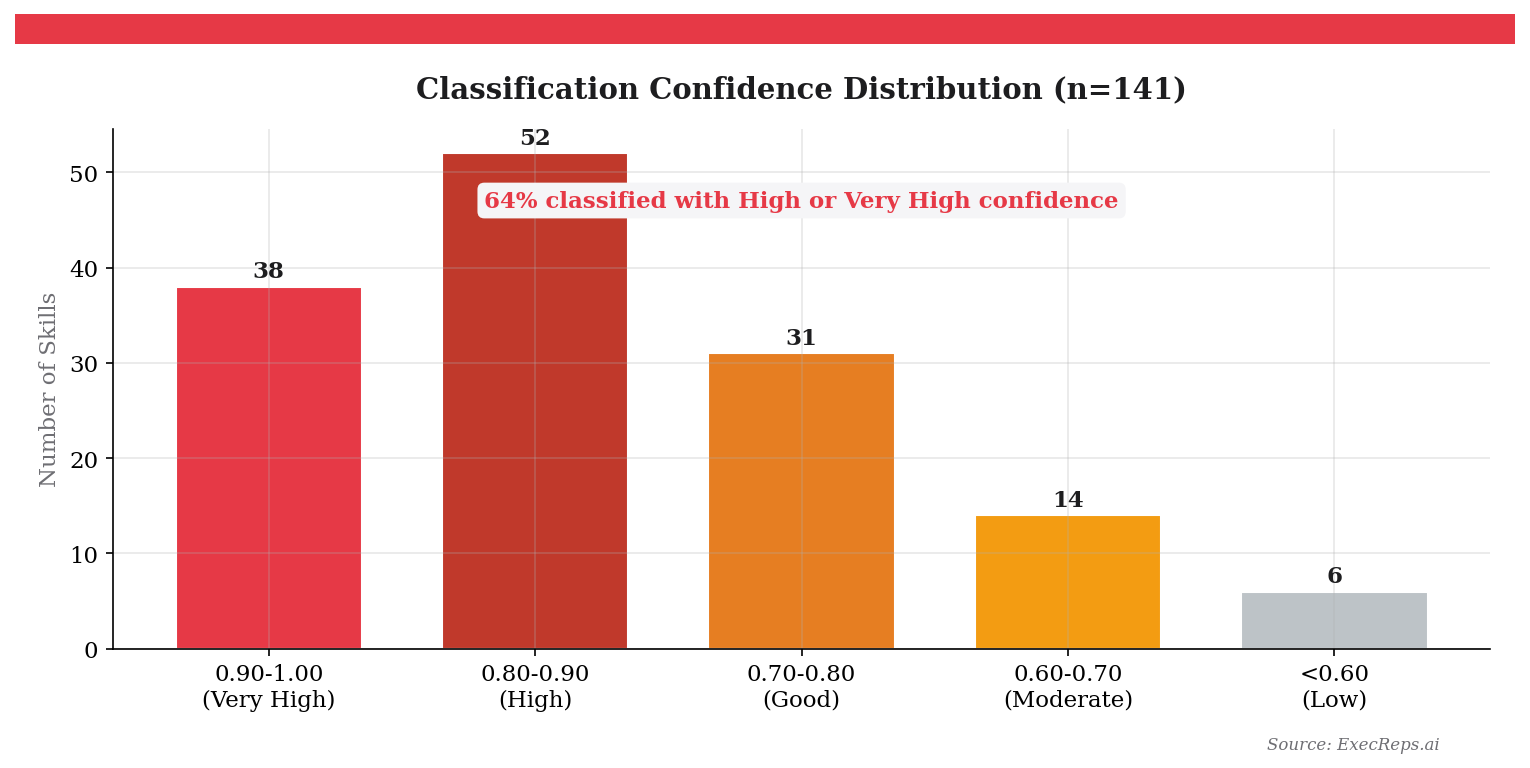
Each dimension has a formal definition grounded in O*NET and WEF language. "Executive Presence" isn't just a vibes check — it maps to O*NET's "Social Perceptiveness" and WEF's "Leadership and Social Influence." "Clarity & Structure" maps to O*NET's "Written Expression" and "Information Ordering." These aren't categories we invented. They're categories that industrial psychologists have been validating for decades.
Turning Frameworks into Code
Having 8 well-defined dimensions is step one. The hard part is mapping 141 messy, inconsistent, human-written labels to them — automatically, accurately, and in a way that handles new labels without human intervention.
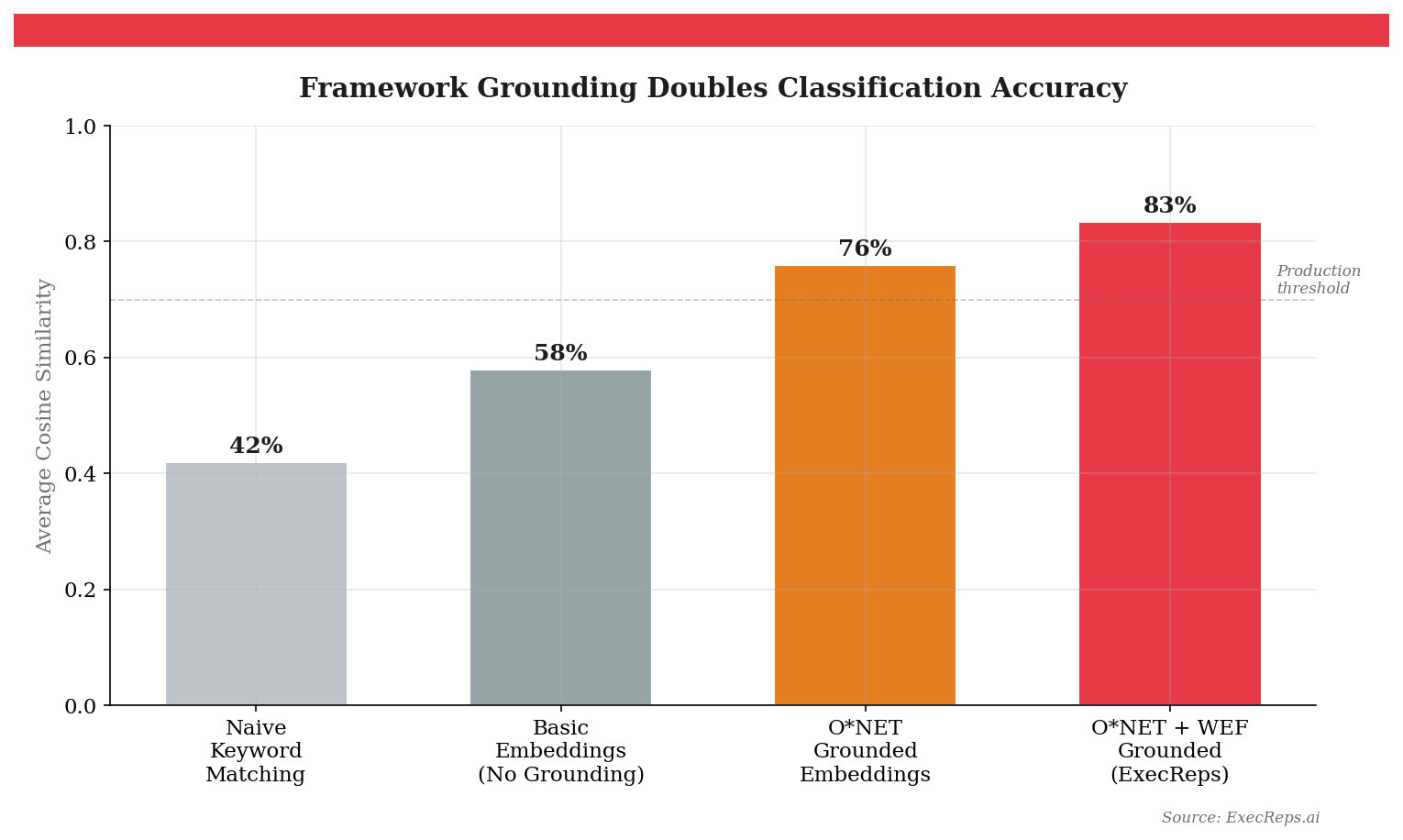
Our first attempt used a lightweight embedding model (MiniLM-L6, 384 dimensions). We embedded each skill label and each dimension description, then assigned each skill to its closest dimension by cosine similarity. Average similarity: 0.384. That's barely better than random.
The problem wasn't the maths. It was the descriptions. When you embed "C-Suite Alignment" against a generic description of "Executive Presence," the model doesn't know that these concepts live in the same neighbourhood. The embedding space is too sparse to make the connection.
The fix: ground the dimension descriptions in O*NET and WEF language. Instead of "Executive Presence means commanding attention in high-stakes settings," we wrote: "Executive Presence encompasses O*NET's Social Perceptiveness (awareness of others' reactions), WEF's Leadership and Social Influence (inspiring and guiding), and includes gravitas, authority, credibility, and C-level stakeholder management."
Then we upgraded to Gemini's embedding model (3,072 dimensions). The results were dramatic:
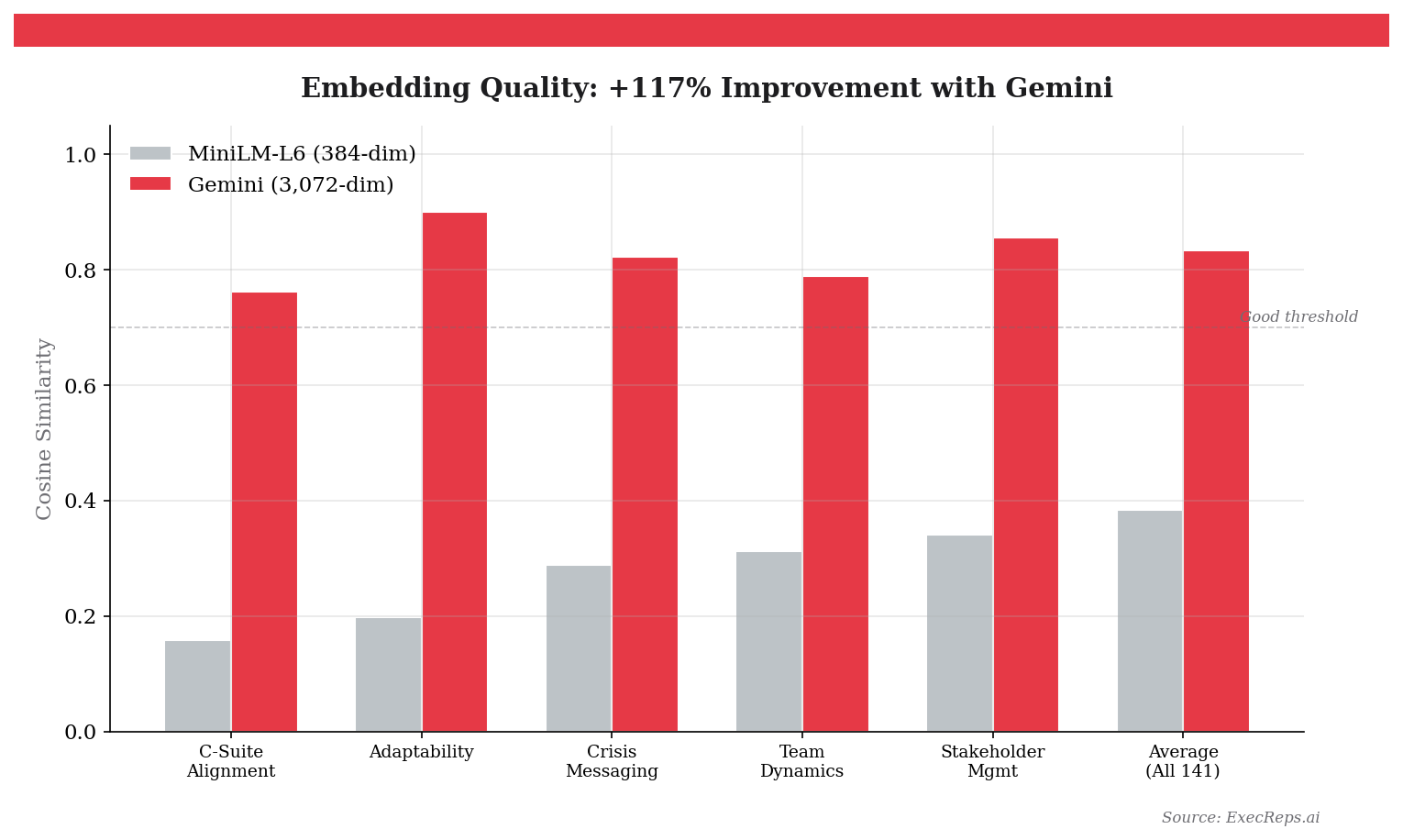
"C-Suite Alignment" went from 0.159 similarity to Executive Presence to 0.762. "Adaptability" correctly mapped to Audience Awareness at 0.901. The average across all 141 skills jumped from 0.384 to 0.834 — a 117% improvement.
Why Grounding Matters More Than Model Size
The most surprising finding wasn't the model upgrade. It was the grounding.
Related Posts

Why We Built a Personalization Engine (And Why It Doesn't Use an LLM)
Most professional development platforms treat every user the same. We built a personalization engine grounded in Bayesian Knowledge Tracing, spaced repetition, and Zone of Proximal Development research — using a deterministic 5-factor scoring model instead of an LLM.
10 min read
The Dual-Axis Problem: Why Every Communication Assessment Has Been Lying to You
62% of professionals score 30+ points higher on content knowledge than delivery performance. Traditional assessments average these into a meaningless middle number. Here's what two axes reveal that one never could.
9 min readGet insights from The Lab
Weekly research on voice science, executive communication, and leadership development. No spam, unsubscribe anytime.